

Taking a step back
When discussing the specific benefits and approaches of leveraging eBPF programs, it is very easy to head directly into a technical rabbit hole. The technology is very detailed and can be used for a wide variety of use cases. Consequently, conversations can quickly get wrapped around specifics while glossing over the fundamental elements of the technology. As is true with any newer technology, it is often helpful to level-set and take a step back to discuss the basics. This post will serve to do just that- provide a high level view into the fundamentals of an eBPF program, and more specifically, into an eBPF program being used for 5G SA visibility.
eBPF is all about the kernel
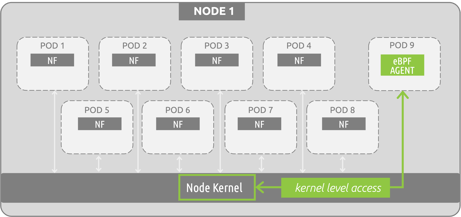
As we have discussed in previous blog posts, eBPF is a way to tie into the primitives of the operating system by deploying at the kernel level of systems.
The diagram on the right shows an example eBPF program being used for monitoring 5G resources. Please note that the “insertion point” for the eBPF program/agent is at the node level, as opposed to the pod/container level (as other agent-based approaches, such as sidecar containers, rely on).
eBPF solutions run as sandboxed programs existing in kernel space, and they do not require any changes to be made to the kernel. This is not a kernel module, but rather a separate entity defined in user space that can introspect container environments as a standalone program running within kernel space. eBPF programs can introspect the entire node environment (all pod-to-pod communications, processes, interfaces, etc.) by deploying as a single pod/container. Its unique focus on kernel instrumentation is one way how eBPF sets itself apart from other cloud-native technologies.
eBPF is all about messages
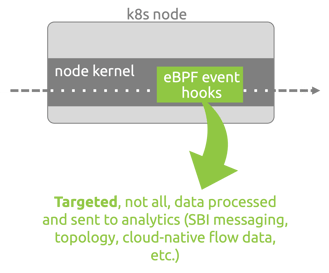
eBPF programs are extremely performant. Unlike sidecar containers, (and vTAPs, span ports, service meshes, etc.) eBPF programs act as event handlers at the kernel level- they are not churning through every piece of information in the environment, instead they are setting hooks for very specific types of traffic.
In the context of a monitoring program, think of it as the difference between focusing on messages vs. focusing on packets. eBPF programs can target and observe the messaging that is core to HTTP/2 based environments. The eBPF program sets hooks in place for the specific messages/events it is looking for (for example, 5G specific SBI messaging) and triggers on those specific hooks to start monitoring the communications.
This approach is far different from the previously mentioned approaches (vTAPS, sidecars, etc.) which are very packet heavy processes and are typically processing all of the data in the environment (as opposed to setting hooks for very specific messages). These legacy approaches require the compute resources to access and process all of this packet data, leading to a substantial strain on production compute resources. eBPF, on the other hand, allows for a base approach that provides an order of magnitude reduction in resource utilization based on:
-its focus on messages, not packets
-the targeted nature of how it is accessing data
eBPF is low footprint
One of the largest considerations while deploying a monitoring solution into a distributed k8s environment is the actual footprint of the solution itself. With an eBPF program, agents are deployed as daemonsets, and auto-scale alongside production resources. This means that there will be one (1) agent per node (doesn’t matter if the node is bare metal or VM based). These agents have visibility into all the activity within and amongst the pods and containers present in that node. Please see the below example, where each node has 10 pods each:
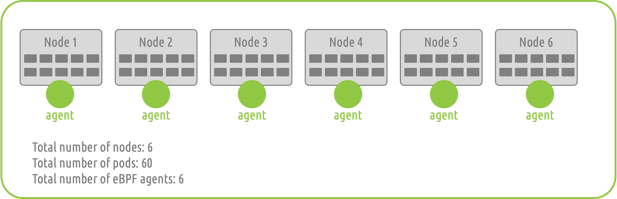
This approach provides a significant reduction in footprint when compared to alternative approaches. The "deployment footprint" of an eBPF program is far smaller than say a sidecar container approach. If using sidecar containers, you would have to deploy sixty (60) agents in the example above, whereas an eBPF based approach only requires six (6) agents.
eBPF is vendor agnostic
Again, eBPF programs access data by integrating into k8s clusters at the node level (linux kernel). eBPF programs do not access information at the container or pod level.
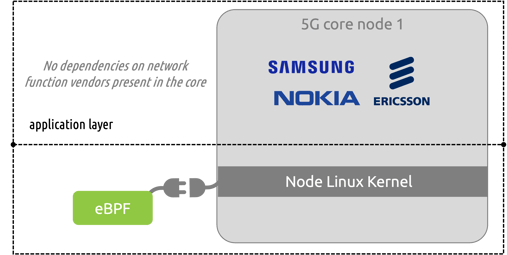
This results in a solution that requires only one integration dependency from the production system- that the kernel supports eBPF. In reality this means that the linux kernel version being run needs to be a version released in roughly the past 13 years (when eBPF was initially adopted and included within the linux foundation). There are zero dependencies on the application layer- meaning there are no dependencies for integration based on the vendors present in the production environment.
This is extremely beneficial across cloud-native environments as a whole, but especially so in 5G telco cloud-native, where the trend over time has been service providers moving away from single-vendor, monolithic solutions to best of breed network function selection where there are now multiple vendors present in all aspects of a 5G stack.
