

As 5G stand alone (SA) environments are beginning to roll out in more earnest, there is an ongoing conversation about how to best support visibility of these container-centric platforms. Network function vendors, carriers, MNOs, and MVNOs all have skin in the game and are taking part in this conversation. At the core of the discussion is a very simple question- what is the best way to instrument and observe these complex and heavily containerized systems?
Traditional tools are no longer viable- this is common knowledge across the ecosystem. The days of deploying taps are long gone, and the days of relying on virtual taps for “cloud resources” have also faded away. We are now firmly in the era of “cloud-native”- the first major evolution of the cloud. Cloud-native has ushered in a new focus on how to best leverage virtual resources and distributed computing, with the core tenet being a shift from VMs and VNFs to containers and CNFs. The challenge now is determining how to best introspect these containerized environments.
Once considered cutting-edge approaches- virtual TAPs, VPC logging, and even VPC mirroring- now all fall inadequately short. Observability solutions today need to get at the container layer traffic, full stop.
There are two main options that have emerged for providing observability of 5G SA environments; although they are very different paths to take from a technological standpoint...eBPF and the sidecar container.
The sidecar container
Sidecar containers have proven to be a go-to for many observability vendors. This method focuses on accessing the container layer of traffic by tying into these environments at the application level. The following diagram is a very simplistic visual for this approach, but it does point out how sidecars are being implemented from a “container access” standpoint. You essentially require a sidecar to exist within every pod, sitting next to the primary workload application/container (in this example, a 5G network function).
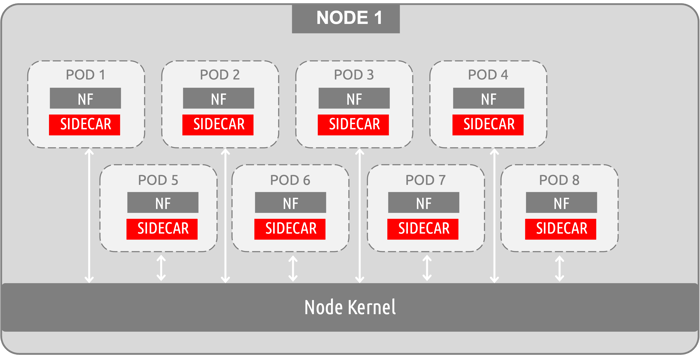
A drawback with this approach is that the primary container and the sidecar container share resources- mainly the same volume and network. Considering that k8s best practices suggest hosting a single container per pod, you are effectively increasing the resources needed to run your primary workload (the NF). The above example shows a very simple architecture of how sidecars tie in, but as you consider large systems and start exploring out-year horizontal scaling and multiple containers-per-pod deployments- the sidecar numbers and resource drain can increase dramatically. Afterall, standard k8s guidance caps the pod to node ratio at 110 pods running per 1 node- this could easily turn into an exponential math exercise (and dilemma).
In reality, this conversation around application-level resource sharing has turned into a very contentious debate between network function vendors and observability vendors. For example, Ericsson has publicly and directly stated that they will not allow third party sidecar containers/agents in their products (their NFs). Whether or not you agree that Ericsson has the right to dictate to an MNO how to run their Kubernetes clusters is a conversation for another time, but the point is that certain vendors do not want sidecar containers running next to (and stealing resources from) their network functions while denying them market share. To take this a step further, it is important to point out that the observability vendor providing the sidecar solution may very well need the NF vendors participation in order to work. Code changes may need to be made by the NF vendor, or at the very least, finer points of integration must be discussed when tying in at the application level and sharing pod volume/network resources.
The use of sidecar observability solutions is rightfully concerning to Ericsson and other NF vendors. First off, there are the application-level resource sharing issues as explained above, but there is another truth that is particularly troubling for 5G mobile environments specifically- sidecars introduce unnecessary network latency. The sidecar acts as a proxy, with all pod-to-pod communications running through that proxy. This results in having to take a latency hit twice for every single communication coming to and from a network function. Keep in mind, 5G is not your average “cloud-native environment”. We aren’t talking about web applications or e-commerce websites- we are talking about a 5G communications network that has promised exactly two things to the general public: dramatically increased speeds and dramatically reduced latency. Paying for unnecessary latency hits due to sidecar containers is a significant consideration in a 5G architecture.
eBPF technology
eBPF (Extended Berkeley Packet Filter) technology has been gaining some serious ground in the cloud-native world. From the long-held support of Netflix and Facebook to major acquisitions of eBPF companies from the likes of Splunk and others, eBPF is here to stay. eBPF is essentially a way to tie into the primitives of the operating system by deploying at the kernel level of systems, as opposed to the application/network level as sidecar containers do. The following diagram shows a basic eBPF program (being used for monitoring 5G resources).
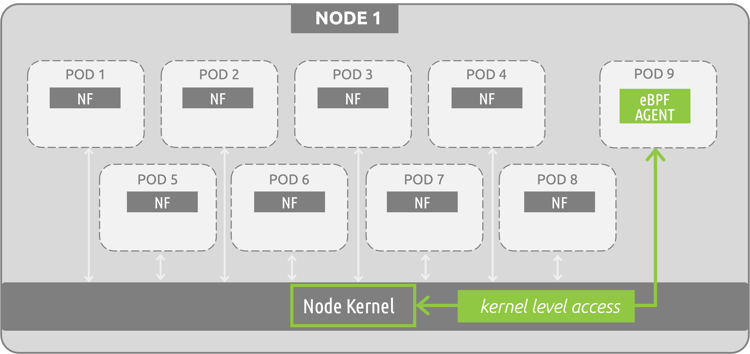
Because eBPF solutions run as a sandboxed program existing in kernel space, they do not require any changes to be made to the kernel. This is not a kernel module, but rather a separate entity defined in user space that can introspect container environments as a standalone program running within kernel space. In this example, the eBPF program can introspect the entire node environment (all pod-to-pod communications, processes, interfaces...) by deploying as a single pod/container…a much more streamlined deployment model than the sidecar container approach.
The advantages of eBPF monitoring span a few different areas, but the most important may very well be the fact that eBPF is extremely performant. Unlike sidecar containers which act as proxies for all pod-to-pod communications (and therefore require resources to sift through all communications), eBPF programs essentially act as event handlers at the kernel level. The eBPF program sets its guidelines in place for the specific events it is looking for (for example, 5G specific SBI messaging) and triggers on those specific hooks to start monitoring the communications. This approach is far different from “monitor everything and pay a resource tax to do so”. It allows for a base approach that can run different functions/capabilities while paying as little as a <1% vCPU resource tax, depending on use case, to gain insight.
The importance of eBPF for 5G observability:
eBPF based solutions are attractive for any cloud-native frameworks, but particularly so for 5G environments. 5G SA environments are a unique entity in the cloud-native world- they are extremely deep systems that have an enormous amount of complexity and abstraction, and as mentioned previously, speed and latency are king. eBPF allows for extremely performant observability solutions to run within these environments that provide very granular insight to data communication exchanges, without affecting latency in any significant way.
One final note on the importance of eBPF for 5G observability brings us back to the conversation of network function vendors and their hesitancy to play nicely with others. As more and more 5G SA environments are being deployed into production, a trend is starting to emerge- that trend is best-of-breed NF vendor selection across the Core, MEC, and O-RAN. With O-RAN being the easiest example to point to, the basic truth is that certain vendors specialize in different areas of the network (or different network functions within the same network area …the Core for example) and can provide the best value to network operators and carriers. This results in companies like Rakuten or DISH (who are leading the charge in 5G SA build outs) to have a wide variety of vendors present in the Core, MEC, and O-RAN. But why does this matter?
eBPF programs can run in a completely vendor agnostic manner- in fact, NF function vendors do not even need to participate for an eBPF observability solution to work. eBPF only has one interdependency- the linux kernel version being used in the environment. If the kernel being used is modern, eBPF programs will work. This means that an eBPF based observability solution can serve as a single pane of glass view across an entire 5G ecosystem- regardless of the vendors that are present. No code changes by the NF vendors, no detailed discussions about integration and pod resources, no wrangling of metrics coming from 10 different vendors- you get a Helm chart and you are ready to deploy (with the benefit of daemonset scaling at that!).

